Pandas创建/读取数据时通常会手动指定索引值或指定索引所在位置,如果不指定则默认索引为(0…n)的数字。由于Pandas各种数据结构的索引使用方法基本通用,故本章使用DataFrame为例。
若无特殊说明,文中所使用数据为用数据为 2016-2018北京高考分数线.xlsx
索引
切片索引
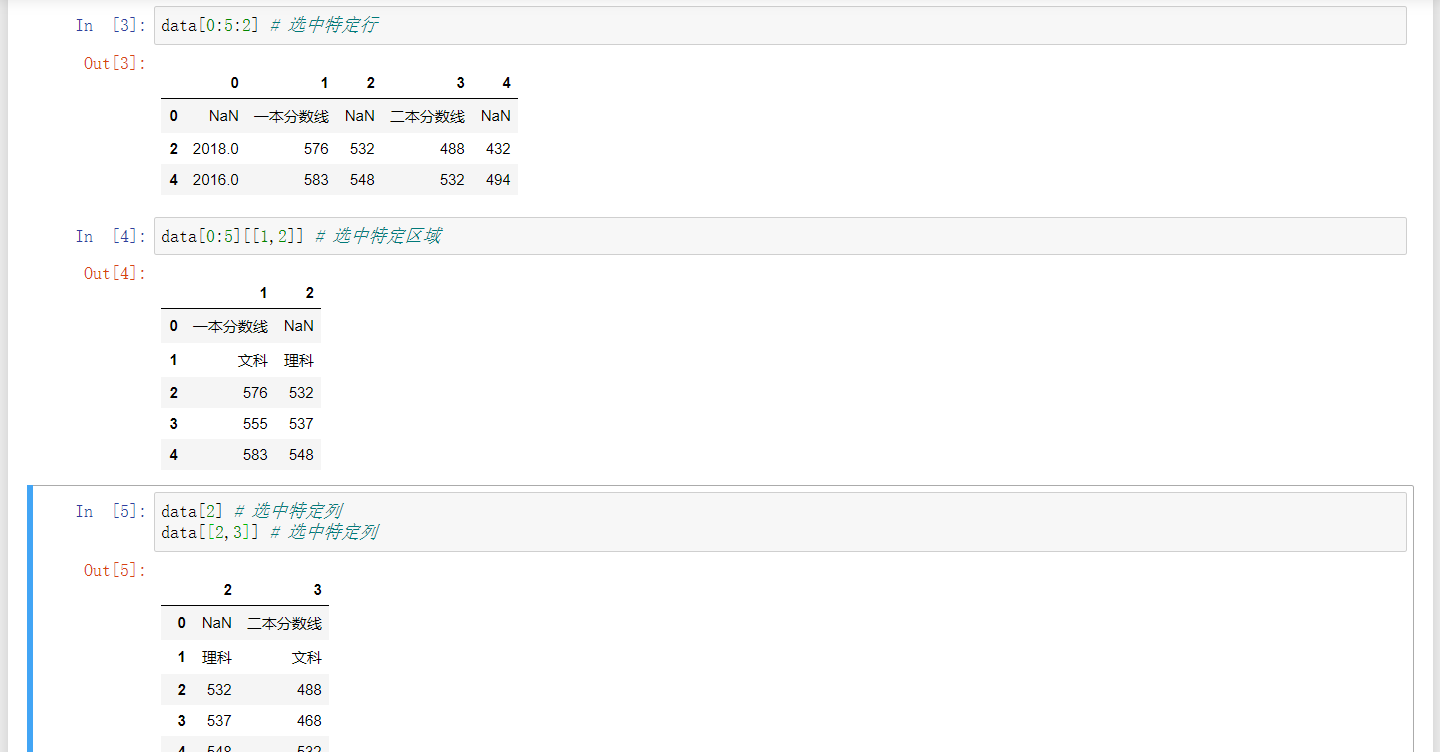
切片索引使用格式为data[row_index][col_index],尝试发现,切片索引与Python数组切片稍有不同,主要有以下几种情况:
- 选中特定行:
data[m:n:step] - 选择特定列:
data['col1']、data[['col1','col2']] - 选择特定区域:
data[row_index][col_index]

切片索引
loc索引
loc索引使用格式为data.loc[row_index][col_index]或data.loc[row_index, col_index],主要有以下几种情况(与上面大致相同):
- 选中特定行:
data.loc[m:n:step](范围[m,n)) - 选择特定列:
data.loc[['col1','col2']] - 选择特定区域:
data.loc[row_index][col_index]
loc索引

iloc索引
iloc索引使用格式为data.iloc[row_index][col_index]或data.iloc[row_index, col_index],主要有以下几种情况(与上面大致相同):
- 选中特定行:
data.iloc[m:n:step](范围[m,n)) - 选择特定列:
data.iloc[[col1,col2]] - 选择特定区域:
data.iloc[row_index][col_index]
iloc索引

以上三种索引方式的差别:
| 索引方式 | 差别 |
|---|---|
| 切片 | row_index既可以使用序号,也可以使用索引名、col_index只能使用索引名 直接通过 DataFrame['column']的方式访问是列索引,直接通过通过切片的方式访问是行索引 |
| loc | row_index和col_index只能使用索引名 直接通过 DataFrame['row_index']和直接通过通过切片的方式访问都是行索引 |
| iloc | row_index和col_index只能使用序号索引 直接通过 DataFrame[row_index]和直接通过通过切片的方式访问都是行索引 |
xi索引
条件索引
条件索引使用格式为data[query]、data.loc[query]和data.iloc[query],使用时目标数据列的数据格式最好一致,本节所使用数据为1:
主要有以下使用场景:
- 直接条件:
data1[data1[1] > 500](文科一本分数线大于500的行) - lambda函数:
data1.iloc[lambda x: ((x[1] > 500) & (x[1] < 550)).tolist()](文科一本分数线大于500小于550的行)
条件索引

NotImplementedError: iLocation based boolean indexing on an integer type is not available。比如直接运行data1.iloc[lambda x: (x[1] > 500) & (x[1] < 550)],则因它返回的是series类型的数据而报错。层次索引
本节使用数据:
构造
- 隐式构造 2
|
|
- 显式构造
|
|
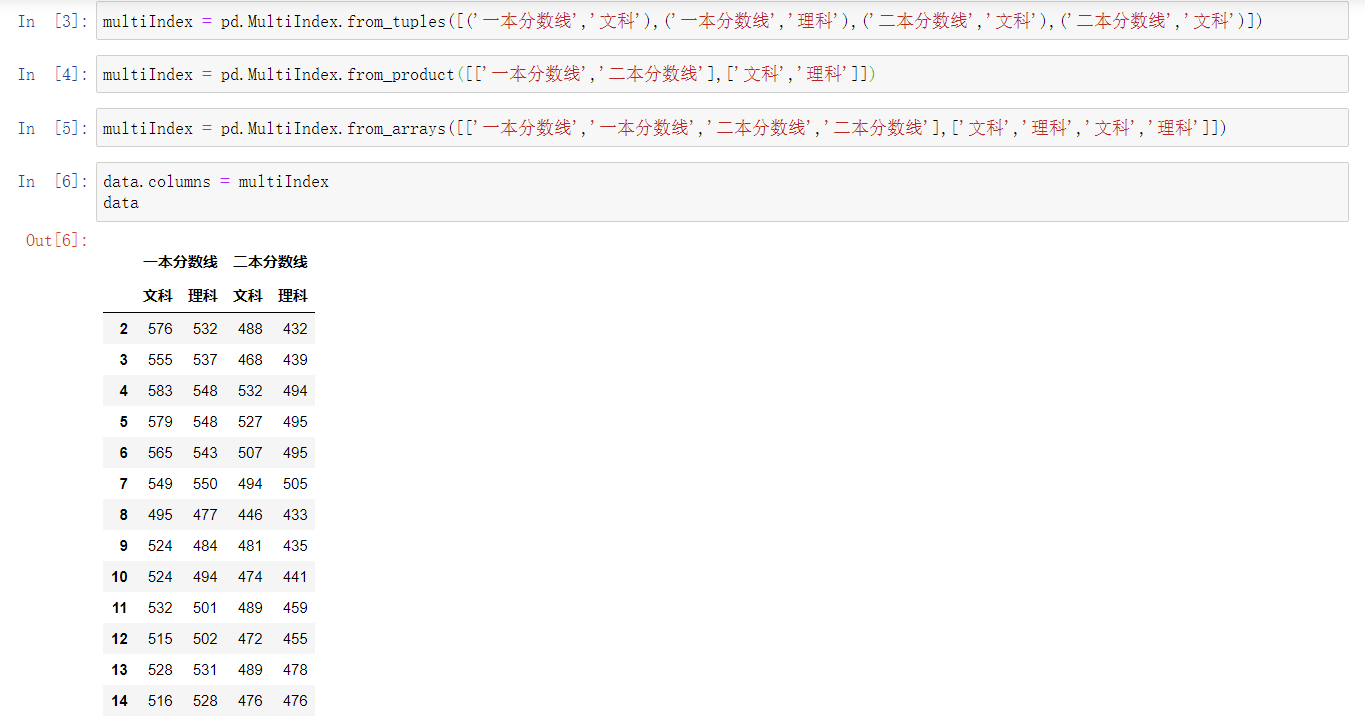
- 指定索引
|
|
访问
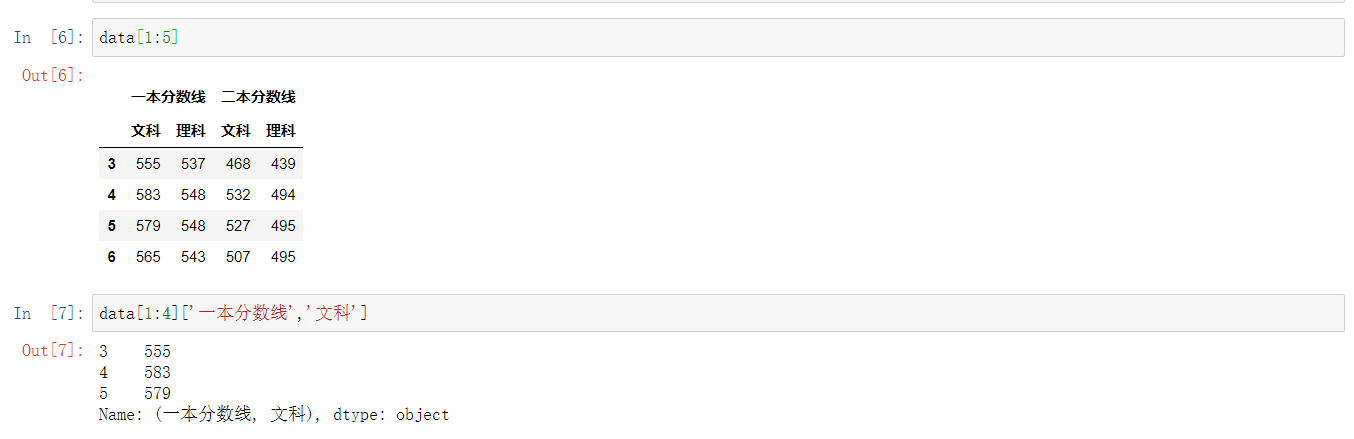
层次索引使用格式为data[row_index][col_index]、data.loc[row_index, col_index],其中多级索引以列表形式输入。例:
|
|
其他
重塑索引
- reindex
pandas中的reindex方法可以为series和dataframe添加或者删除索引3,函数原型为:pd.reindex([index, columns, method, copy, level, fill_value, limit])。
|
|
- reset_index
DataFrame可以通过reset_index还原索引,重新变为默认的整型索引,函数原型为:
|
|
其中level控制了具体要还原的那个等级的索引,drop为False则原索引会被设置为新的列数据,否则会删除原索引。
参考
-
SNII_629. [Pandas]数据选取/数据切片. CSDN. [2018-10-09] ↩︎
-
你好,小帝. pandas层次化索引. 博客园. [2017-10-26] ↩︎
-
我是小蚂蚁. pandas中的reindex用法. CSDN. [2018-10-26] ↩︎